Hukommelsesteori
Inden du begynder at kode og benytte dine egne klasser, er du nødt til at kende til grundlæggende hukommelsesteori. Ikke fordi du på dette niveau skal være superbevidst om performance, men fordi den mest klassiske begynderfejl i objektorienteret programmering er manglende forståelse for forskellen på værdibaserede og referencebaserede typer.
Information til undervisere
At forstå forskellen på reference- og værdibaserede typer er nok en af de vigtigste ting i det at lære objektorienteret programmering. Her er forskellige afsnit samt videoer som kan bruges til at forklare forskellen. Hent evt samtlige Powerpoint filer der ligger til grund for videoer - de kan være bedre at gennemgå manuelt i forbindelse med undervisning.
Som nævnt flere gange i bogen har du fem typer af vælge i mellem i C#:
- Klasse
- Struktur
- Enumeration
- Delegate
- Interface
De to første – klasser og strukturer – bruger du som også nævnt til at skabe skabeloner for instanser, og disse instanser kan indeholde værdier, som placeres i felter. I frameworket har Microsoft også gjort brug af klasser og strukturer til de fleste af de skabeloner, der er til rådighed under System-namespacet. Af de mere kendte strukturer kan blandt andet nævnes System.Int32 (int) og System.DateTime. Af kendte klasser kan nævnes System.String (string), System.Random, System.Array og mange andre.
Du har frit valg og kan vælge at kode eksempelvis en terning som en klasse:
class Terning
{
public int Værdi;
public void Ryst()
{
Random rnd = new Random();
this.Værdi = rnd.Next(1, 7);
}
}
som kan benyttes således:
Du kan også vælge at benytte en struktur:
internal struct Terning
{
public int Værdi;
public void Ryst()
{
Random rnd = new Random();
this.Værdi = rnd.Next(1, 7);
}
}
som benyttes på præcis samme måde:
Du kan ikke se forskel i brugen af typen, men på typeniveau er der forskel. Eksempelvis kan en struktur ikke indgå i et arvehierarki. Men den helt store forskel skal findes i, hvordan værdier opbevares i hukommelsen – og det er du nødt til at forstå.
Diagram over hukommelsen
Når en applikation starter, bliver den tildelt et område af hukommelsen til at opbevare instruktioner og midlertidige data:
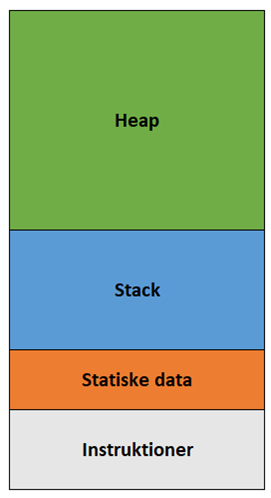
Instruktioner (den kompilerede applikation) og statiske data kan du se bort fra lige nu, men stack og heap er vigtige begreber i mange programmeringssprog. I virkeligheden er brugen af stack og heap meget kompleks og en del af det, man lærer i teori relateret til udvikling af kompilere, men i grundlæggende C# behøver du kun forstå det overordnet.
Disse to områder af hukommelsen fungerer på vidt forskellige måder og spiller en afgørende rolle for, hvordan dine programmer opbevarer og håndterer data.
Stack
Stacken kan betragtes som et organiseret, lineært hukommelsesområde, der anvendes til at gemme lokale variabler, metoder og funktionskald. Tænk på det som en stak af tallerkener: Når du kalder en metode, lægger du dens data (parameter- og lokale variabler) oven på stakken. Når metoden afslutter, fjernes det øverste lag igen. Denne LIFO-struktur (Last In, First Out) gør adgangen til data på stacken hurtig og effektiv. Navnet “stack” er da også en direkte reference til denne stak-lignende organisering.
Konceptet med stack-baseret hukommelseshåndtering kan spores tilbage til tidlige programmeringsmodeller i 1960’erne, hvor CPU-arkitekturer introducerede stakbaserede instruktioner, og sprogdesignere hurtigt så potentialet i at udnytte disse mekanismer til at organisere funktionskald og lokale variable på en simpel og overskuelig måde.
Heap
Hvor stacken er streng i sin organisering, er heapen mere fleksibel. Heap-hukommelsen benyttes, når du opretter objekter ved hjælp af f.eks. new i C#. Disse objekter gemmes et vilkårligt sted i heapen, og du får en reference til objektet, som peger på denne placering. Navnet “heap” (bunke) understreger, at hukommelsen her ikke nødvendigvis er organiseret i en bestemt rækkefølge – det er nærmere en stor “bunke” af hukommelse, hvor man kan tage og aflevere plads efter behov.
Introduktionen af heap-baseret allokering opstod også tidligt i programmeringens historie. Allerede i 1970’erne blev teknikker til dynamisk hukommelsesallokering introduceret i sprog som C. Med tiden har disse teknikker udviklet sig, og C# er et moderne eksempel, hvor garbage collectoren automatisk håndterer frigivelsen af objekter i heapen. Det gør udviklerens arbejde lettere, da man ikke længere manuelt skal styre, hvornår objekter skal fjernes fra hukommelsen.
Brug af stack og heap
I et typisk C#-program vil mindre datatyper som int og bool som udgangspunkt ende på stacken, mens objekter oprettet med new havner på heapen. Når programmet kører, sørger runtime-miljøet for, at stacken vokser og skrumper i takt med metodekald, mens heapen fyldes op med objekter, der forbliver der, indtil garbage collectoren fjerner dem.
Denne opdeling giver en god balance mellem ydeevne og fleksibilitet: Stacken er hurtig og simpel at håndtere, mens heapen giver friheden til at oprette komplekse dataobjekter dynamisk. Denne model er blevet fundamentet for, hvordan moderne programmeringssprog – herunder C# – administrerer hukommelse og sikrer effektiv kørsel af programmer.
Stack og stack-frame
Helt overordnet og konceptuelt består en stack altså af et område i hukommelsen, hvor de variabler, du har defineret i en applikation, er placeret. Alle variabler, der er defineret i en metode, er placeret i denne stack. Spørgsmålet er hvad variablerne indeholder, og det afhænger af, om variablerne er værdibaserede eller referencebaserede. Hvis variablerne er værdibaserede, indeholder de en værdi, mens de referencebaserede indeholder en reference til et objekt på heapen.
Note
Alle variabler er placeret i stacken. Spørgsmålet er, hvad variablerne indeholder - værdier eller referencer.
Her er en video som viser hvordan værdibaserede variabler opfører sig i hukommelsen.
Stack-frames
Stacken er igen opdelt i mindre enheder kaldet en stack-frame, og hver stack-frame er relateret til en metode, der bliver kaldt, når programmet eksekveres. Du har tidligere lært om virkefelter, og som du sikkert kan huske, så har en metode (eller andre medlemmer) sit eget virkefelt med helt isolerede variabler. Disse variabler er kun tilgængelige i denne metode. Hvis de skal benyttes i andre metoder, må de sendes med som argumenter.
Hvis du arbejder med en konsol-applikation, vil applikationen starte i Main-metoden, som runtime vil sørge for at afvikle. Applikationens stack har derfor en enkelt stack-frame, som vi kan relatere til Main-metoden. I denne stack-frame kan der angives de variabler, der er defineret og tildelt værdier eller referencer.
Forestil dig at du afvikler følgende applikation, og at du stopper afvikling ved diagram-kommentaren:
Så vil du kunne skabe et diagram som følger:
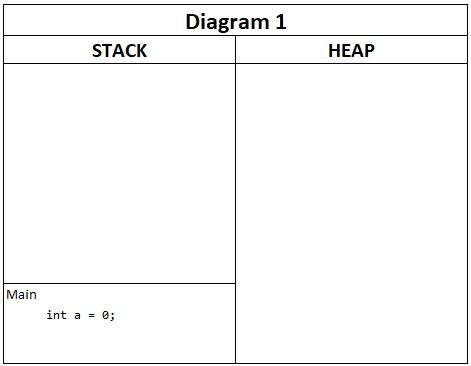
Navnet ”stack” kommer fra det faktum, at en metode kan kalde en anden metode, som også har sin egen stack-frame, og denne (konceptuelt) lægges oven på den forrige. Se følgende eksempel:
int a = 0;
// Diagram 1
Metode1();
// Diagram 4
void Metode1()
{
// Diagram 2
int a = 0;
// Diagram 3
}
Diagrammerne ser således ud:


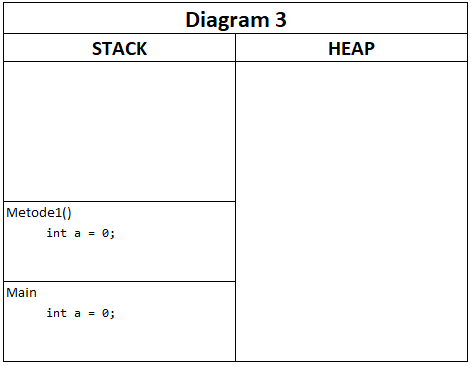

Som det fremgår, er hver metode indkapslet i sin egen lille sandkasse, og alt hvad der benyttes af variabler, lever kun her. Såfremt Metode1 kalder en anden metode, vil der blot dukke en ny stack-frame op som afvikles og forsvinder igen.
Eksamensspørgsmål
Lad os se på det klassiske C# eksamensspørgsmål, der tager udgangspunkt i følgende kode:
Terning1 t1 = new Terning1() { Værdi = 1 };
Terning1 t2 = t1;
t1.Værdi = 6;
// Hvad er værdien af t1.Værdi og t2.Værdi
struct Terning1
{
public int Værdi;
}
class Terning2
{
public int Værdi;
}
Hvad tror du, svaret er på spørgsmålet stillet som en kommentar i koden? Og inden du svarer – husk at t1 og t2 er af typen Terning1, som er en struktur. Du bør skrive koden selv og prøve det af – men et diagram afslører tydeligt svaret:

Værdier fra t1 er kopieret over i t2, og når der efterfølgende rettes i t1, har det ikke nogen konsekvens på t2.
Så svaret er, at t1.Værdi = 6 og t2.Værdi = 1.
Værdibaserede argumenter
Hvis en metode har argumenter, kan du se dem som variabler i selve metoden. Værdierne fra den kaldende metode kopieres ind i den kaldte metode:
Koden resulterer i følgende:
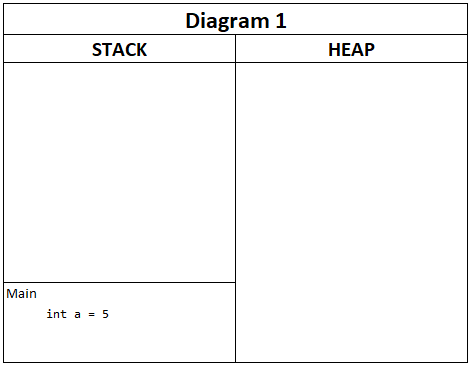
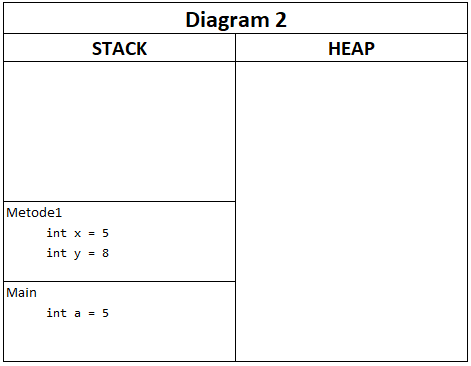
Bemærk, at værdien i a kopieres ind i den kaldende metode og lever sit helt eget liv i sin helt egen lille verden. Når Metode1 er afviklet, forsvinder x og y og de andre variabler i Metode1. Og blot for en god ordens skyld – variablerne x og y kunne lige så godt være kaldt a og b. Det har ingen betydning for den kaldende metode (Main).
Her er en video som viser hvordan stack-frames opfører sig i hukommelsen.
Heap
Hukommelsen på heapen er en anden sag. Her opbevares objekter, og du får en reference til objekterne. En reference er blot en adresse til objektet, og det er denne reference, der opbevares på stacken. Når du opretter et objekt med new, vil objektet blive placeret et vilkårligt sted i hukommelsen, og du får en reference til objektet. Det kaldes også allokering af hukommelse. Når objektet ikke længere er i brug, vil en feature kaldet en garbage collector fjerne objektet fra hukommelsen. Det kaldes deallokering af hukommelse.
Info
En struktur er en værdibaseret type, mens en klasse er en referencebaseret type!
De diagrammer, du har set indtil nu, har udelukkende bestået af Int32 variabler, og da Int32 er en struktur, opbevares værdier direkte på den førnævnte stack. Men som du så i starten af kapitlet, kan du skabe både strukturer og klasser. Enten:
eller:
Forskellen på brugen af de to typer kommer rigtig til syne, når du tegner diagrammer over, hvad der sker, når du skaber instanser. Med udgangspunkt i Terning1 og Terning2 kan der oprettes instanser som følger:
Terning1 t1 = new Terning1() { Værdi = 1 };
Terning2 t2 = new Terning2() { Værdi = 2 };
Console.WriteLine(t1.Værdi); // 1
Console.WriteLine(t2.Værdi); // 2
Et diagram, der viser, hvordan hukommelsen ser ud, når instanserne er oprettet, ser således ud:
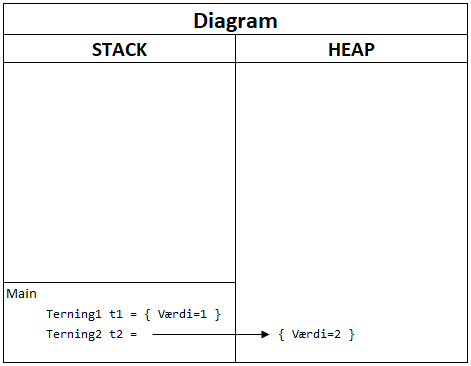
Som det fremgår, indeholder t1 en værdi og er placeret på stack’en og t2 indeholder en reference og er placeret på heap’en. Det er vigtigt, at du forstår forskellen på værdibaserede og referencebaserede typer, da det er en klassisk begynderfejl at forveksle de to.
Eksamensspørgsmål
Lad os så se på endnu et klassisk eksamensspørgsmål der tager udgangspunkt i følgende kode:
Terning2 t1 = new Terning2() { Værdi = 1 };
Terning2 t2 = t1;
t1.Værdi = 6;
// Hvad er værdien af t1.Værdi og t2.Værdi
struct Terning1
{
public int Værdi;
}
class Terning2
{
public int Værdi;
}
Hvad tror du, svaret er på spørgsmålet stillet som en kommentar i koden? Og igen, inden du svarer – husk at t1 og t2 er af typen Terning2, som er en klasse.
Diagrammet afslører svaret meget tydeligt:
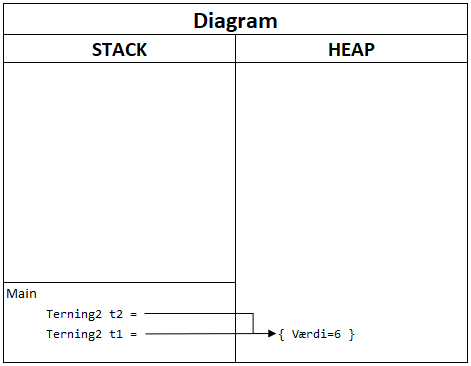
Variablerne t1 og t2 indeholder referencer til et sted i hukommelsen, så instruktionen t2 = t1 kopierer referencen fra t1 til t2. Da både t1 og t2 dermed peger på den samme instans i hukommelsen, er svaret, at t1.Værdi er lig med 6 og t2.Værdi også er lig med 6.
Det er vigtigt, du forstår denne helt basale forskel på variabler af strukturer og variabler af klasser, så du bør prøve ovennævnte kode af selv og tegne et par diagrammer.
Her er en video som viser påvirkning af hukommelse ved referencebaserede typer.
Referencebaserede argumenter
Viden om forskellen på værdibaserede og referencebaserede typer er også vigtig, når du arbejder med metoder. Hvis du sender en værdibaseret variabel som argument til en metode, vil værdien altså blive kopieret ind i metoden. Men hvis du sender en referencebaseret variabel som argument, vil referencen kopieres ind i metoden. Dette betyder, at du kan ændre på objektet, som referencen peger på, og ændringerne vil være synlige uden for metoden.
I C# findes der ikke nogle kodeord som grundlæggende (se dog evt. her) kan ændre denne funktionalitet. Det er altid referencer, der sendes, og derfor kan du altid ændre på objekter, som sendes som argumenter til metoder. Du kan naturligvis skabe immuatable objekter, så kan du ikke ændre på objekternes tilstand, men grundlæggende er det altid referencer, der sendes.
Eksamensspørgsmål
Her er endnu et klassisk eksamensspørgsmål, der tager udgangspunkt i følgende kode:
Terning1 t1 = new Terning1() { Værdi = 1 };
Terning2 t2 = new Terning2() { Værdi = 1 };
Metode1(t1, t2);
// Hvad er værdien af t1.Værdi og t2.Værdi
void Metode1(Terning1 ts, Terning2 tc) {
ts.Værdi = 6;
tc.Værdi = 6;
}
struct Terning1
{
public int Værdi;
}
class Terning2
{
public int Værdi;
}
Der bliver skabt en instans af Terning1 (struktur) og en instans af Terning2 (klasse), og variablerne benyttes som argumenter i en metode, hvor værdien sættes til 6. Hvad er værdien af terning1.Værdi og terning2.Værdi efter kaldet til metoden? Prøv at tegne diagrammet selv – det vil afsløre svaret:

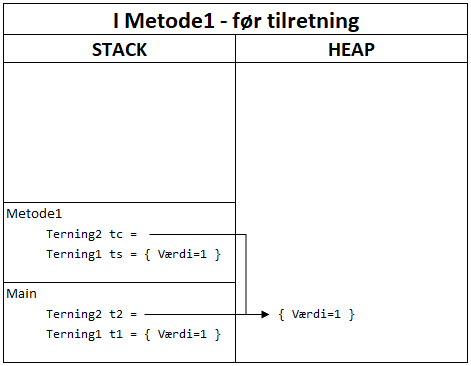


Efter kaldet til Metode1 vil t1.Værdi have værdien 1 og t2.Værdi have værdien 6. Årsagen skal findes i forskellen på typerne – ved kaldet til Metode1 bliver værdien af t1 og referencen til t2 kopieret ind i metoden. Derfor vil en tilretning af t1 ikke have nogen konsekvens.
Her er en video som viser påvirkning af hukommelse ved referencebaserede typer.